Dans le cadre des nouveaux services proposés par l’infrastructure Istex, opérée par l’Inist-CNRS, voici la présentation de 2 outils autonomes et interopérables pour la fouille de textes ou TDM (Text and Data Mining).

Vous souhaitez indexer, attribuer des mots-clés à vos documents (résumé, texte intégral) ? Deux web services répondent à ce besoin avec des approches différentes. Le premier indexe chaque document, le second extrait les termes spécifiques du corpus.
Teeft
En tant qu’utilisateur de l’infrastructure Istex, vous savez que le texte intégral des documents est indexé à l’aide de Teeft.
Notre équipe vous permet d’accéder à cet outil grâce au web service du même nom. Ainsi, vous pouvez indexer vos propres résumés et textes intégraux.
Son objectif ? Il extrait, par défaut, les 5 termes les plus spécifiques d’un texte en anglais ou en français mais vous pouvez le paramétrer et récupérer le nombre de termes que vous souhaitez. Cette indexation permet ainsi d’avoir une idée de ce dont il est question dans le texte.
La méthode ? Il commence par découper le texte en phrases, puis en tokens (des mots, typiquement). Ensuite, il étiquette grammaticalement ces tokens (nom, adjectif, verbe, …) en tenant compte de la langue. Il fait de ces tokens des termes. Sont enlevés les mots vides (différents selon la langue), les termes trop courts, trop longs, les termes alphanumériques contenant moins de lettres que de chiffres. A l’aide d’un paramétrage, on peut supprimer ou conserver les nombres (les termes exclusivement constitués de chiffres).
Puis l’algorithme calcule une spécificité pour chaque terme, en se basant sur sa fréquence par rapport à sa fréquence d’apparition moyenne dans des textes génériques de la langue. Enfin un filtre permet de ne garder que les termes les plus spécifiques.
Pour en savoir un peu plus, rendez-vous sur la fiche descriptive du web service
TermSuite
Ce web service s’appuie sur l’outil TermSuite pour faire une extraction terminologique à partir d’un corpus de textes en anglais ou en français.
Son objectif ? Il extrait, par défaut, les 500 termes les plus spécifiques au corpus correspondant à tous les fichiers textes mais vous pouvez le paramétrer et récupérer le nombre de termes que vous souhaitez. Cette indexation permet d’avoir une idée des sujets abordés par l’ensemble des fichiers et de commencer la constitution d’un vocabulaire contrôlé.
La méthode ? Il s’agit d’un web service asynchrone. Le programme utilisé est TermSuite. Après des analyses linguistiques, est effectuée l’extraction terminologique sur laquelle est calculée la spécificité (termhood) du terme par rapport à un corpus de langue générale. Enfin un filtre statistique permet de ne garder que les termes les plus spécifiques.
La sortie est alors une liste de 500 termes par défaut. Chaque mot est précédé de son étiquette grammaticale (n pour nom, a pour adjectif, …) et chaque terme est associé à sa fréquence d’apparition dans le corpus.
Pour en savoir un peu plus, rendez-vous sur la fiche descriptive du web service
Leur utilisation ? Comme pour une partie des autres web services :
– via Lodex, un outil open source de visualisation et de traitement de données structurées développé à l’Inist. Cette plateforme permet d’importer vos données, de les traiter selon vos besoins, avec nos web services, de visualiser les résultats de façon dynamique et enfin de les publier sous forme de site web.
Attention, dans Lodex, Teeft est considéré comme un enrichissement et TermSuite comme un précalcul.
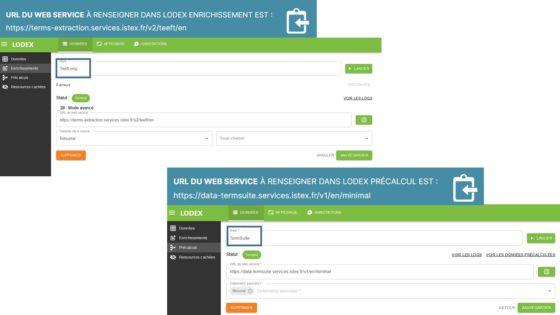
– via IA Factory, interface de chargement de corpus et d’exécution d’outils TDM :
- Teeft : sélectionnez « Le résultat produit une liste de termes associés à leurs fréquences » ou « Le résultat produit une liste de termes associés à leurs fréquences », en fonction de la langue des documents de votre corpus.
- TermSuite : sélectionnez « Extraction des termes d’un fichier corpus en anglais » ou « Extraction des termes d’un fichier corpus en français », en fonction de la langue des documents de votre corpus.
– via une ligne de commandes (outils curl, wget, ou autres, pour des utilisateurs plus avancés)
Le prochain article dédié aux web services sera consacré à l’extraction d’entités nommées.
En attendant, utilisez Teeft et TermSuite et venez consulter le catalogue des web services ISTEX TDM pour trouver des outils d’aide à l’analyse de données et de textes.
Valérie Bonvallot pour l’équipe TDM

Besoin d'aide ?
Consultez notre Faq, la documentation Istex ou nos tutoriels
N’hésitez pas à nous contacter si besoin, nous reviendrons rapidement vers vous !
Écrivez-nous
